为啥接触到js逆向?
在学习python爬虫框架爬取网站数据的时候发现大多数网站都不能直接爬取,在前端js文件中做了许多反爬限制,需要对js进行逆向解析,而我正好是一名前端开发工程师,所以在稍微学习了一下后基本了解了一些技巧。
前置准备
1逆向环境
- Node.js14.0以上版本
_官网下载地址:https://nodejs.org/en/download/
_教程:https://www.runoob.com/nodejs/nodejs-install-setup.html - Chrome浏览器 / Firefox浏览器
_Chrome官网:https://www.google.cn/intl/zh-CN/chrome/
_Firefox官网:http://www.firefox.com.cn/ - VScode
_官网下载地址:https://code.visualstudio.com
谷歌浏览器调试
- 1 右键页面 -> 检查 | 按F12触发
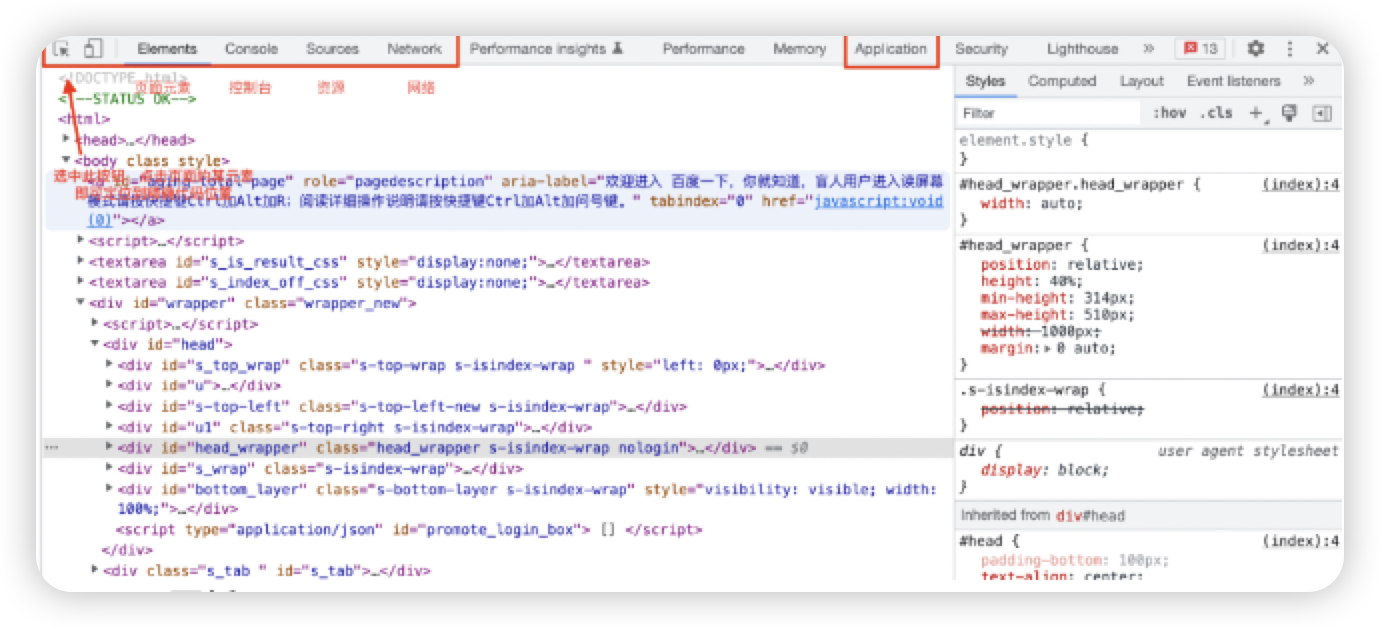
- 2 Element面板
*下元素断点:选择Break on->subtree modification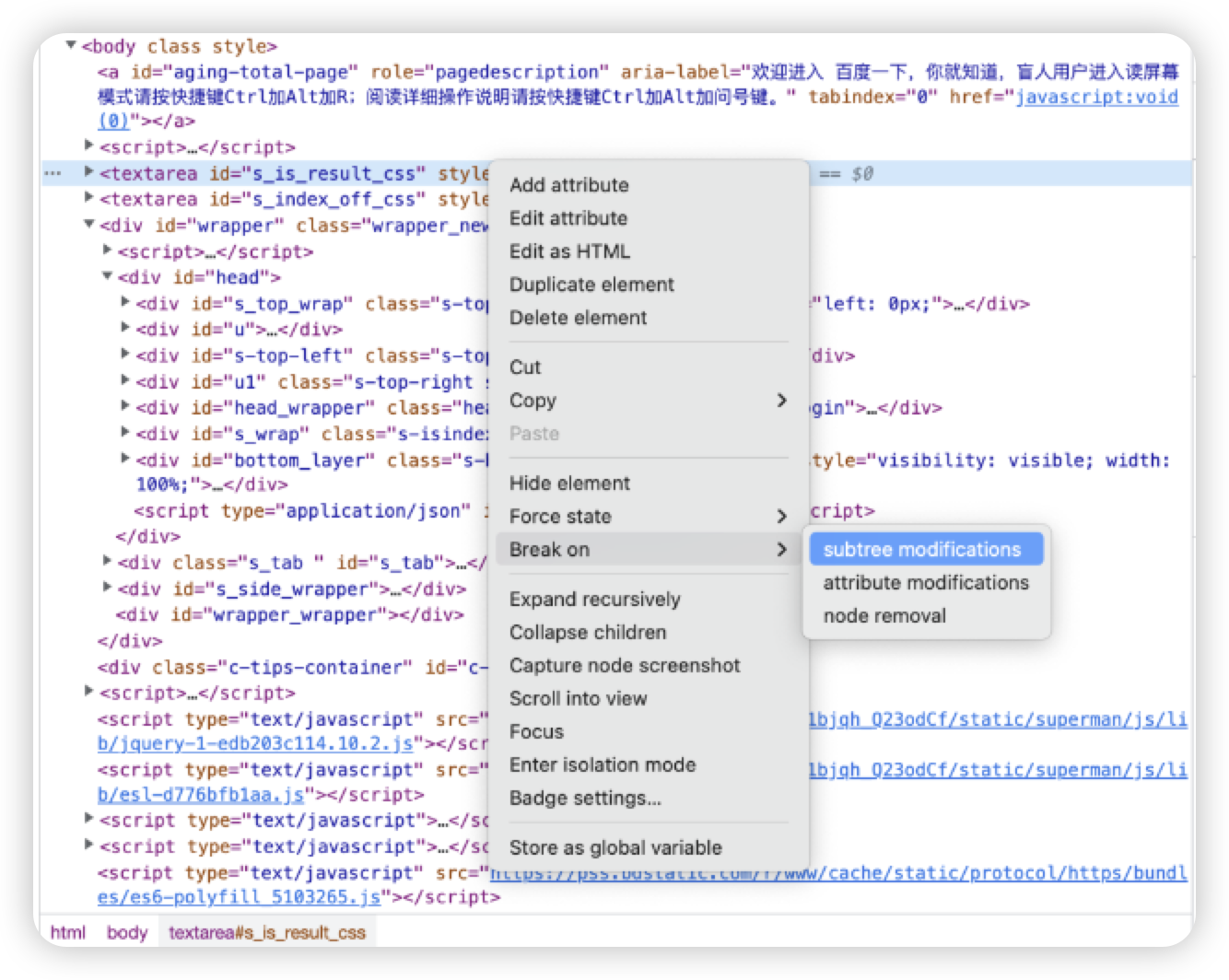
- 3 Console面板
勾选如下设置,此面板主要用于查看开发日志以及与JS交互。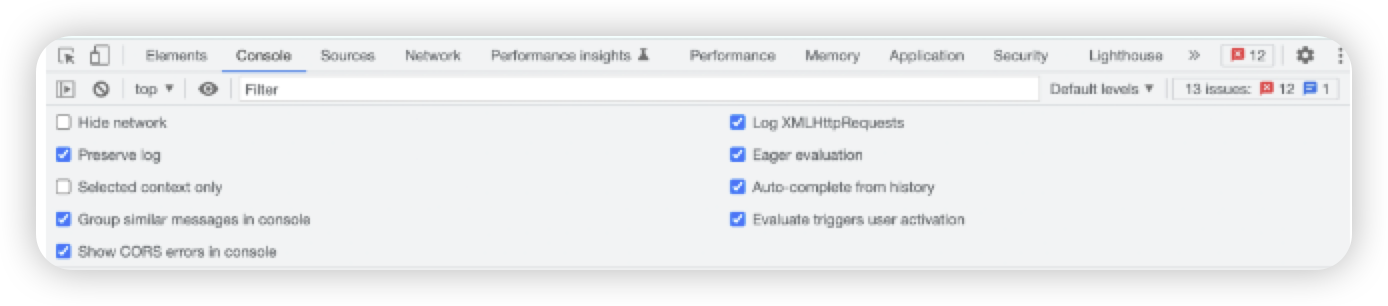
- 4 Sources面板
此处有3个模块在逆向过程常用,在以后教程会单独举例讲。
Page板块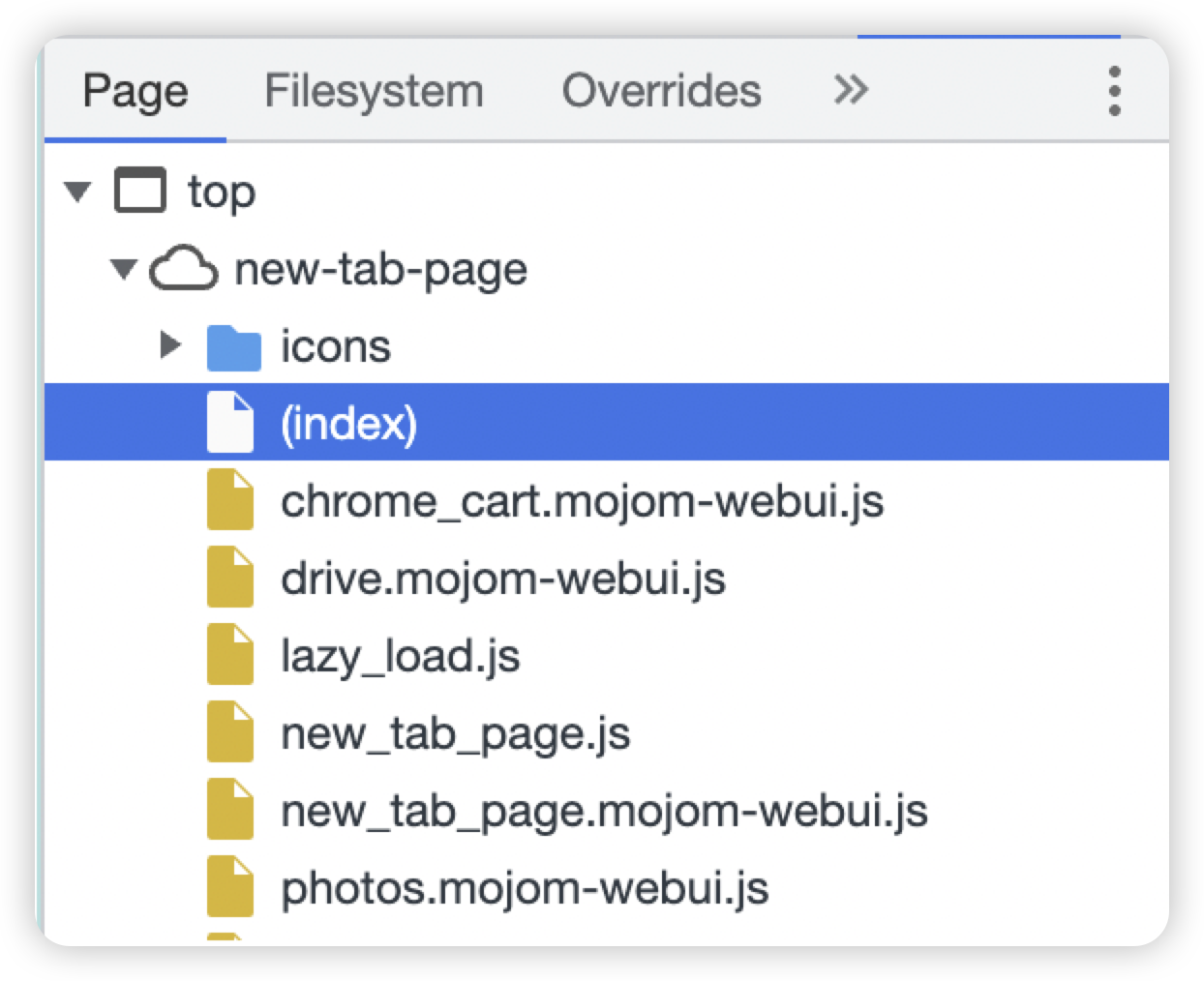
页面加载所加载的资源都在这里,具体内容可以点开后下断点。
Overrides板块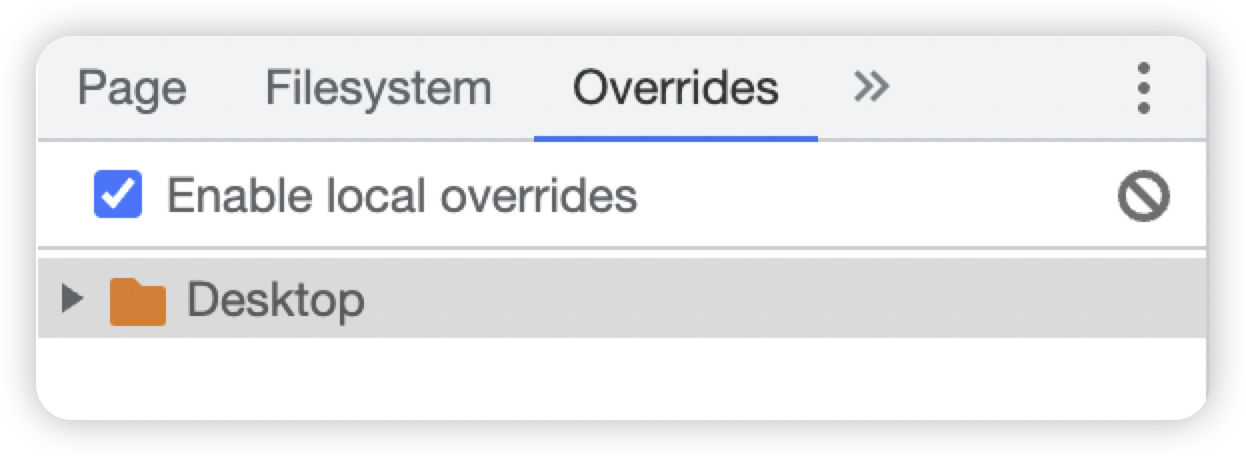
此板块用于项目重写,在Page页选择跳到Overrides的话就可以直接本地替换掉原有的文件。
Snippets板块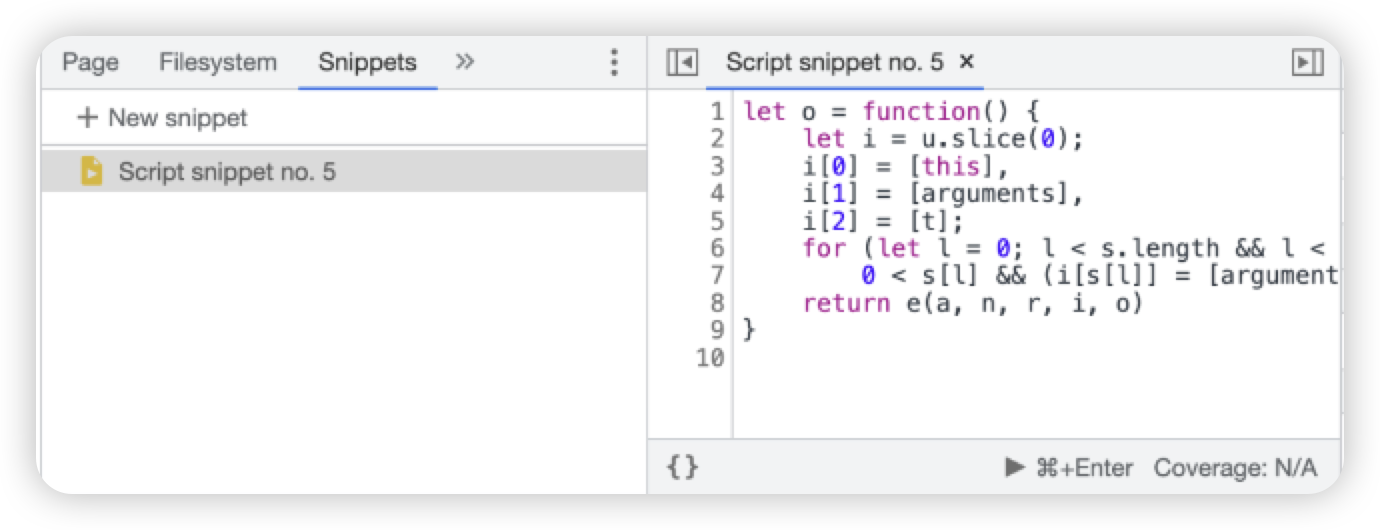
- 5 Network板块
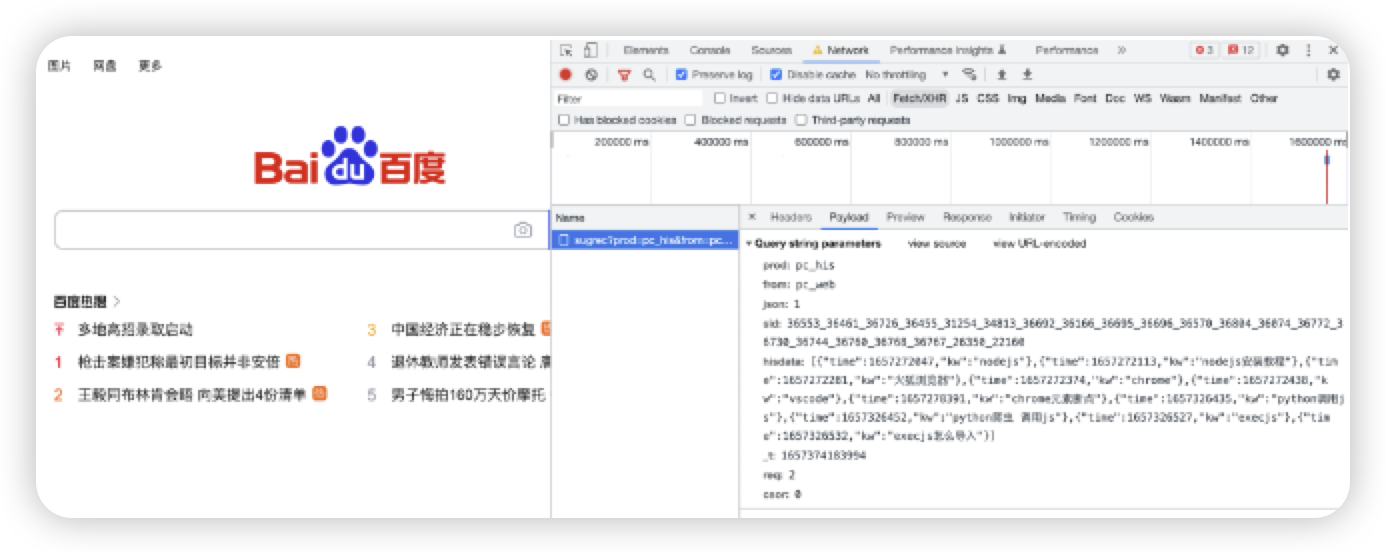
可以看到网页加载时的请求链接,可以看到加密的参数这些情况,具体在后面会说到。

